Odprti modeli postajajo dovolj dobri, da številnim ekipam ni več treba začeti z zaprtim API-jem in upati, da bo ponudnikov načrt nekoč dohitel njihove domenske potrebe. Zanimivejše vprašanje danes ni več, ali se odprti model da prilagoditi. Vprašanje je kako ga prilagoditi, ne da bi pri tem sežgali denar, čas in operativno potrpežljivost.
Za večino organizacij je praktičen odgovor še vedno LoRA — Low-Rank Adaptation. Ne zato, ker bi bil moderen, ampak zato, ker zadene ravno tisti nerodni srednji prostor, v katerem živijo resnični projekti: omejena računska moč, nepopolni podatki, pritisk hitrih iteracij in potreba, da osnovni model ostane stabilen, medtem ko specializiramo njegovo vedenje.
Če želite odprti model učiti za domensko delo, je LoRA običajno prva metoda, ki jo je vredno preizkusiti, in zadnja, ki bi jo morali prehitro opustiti.
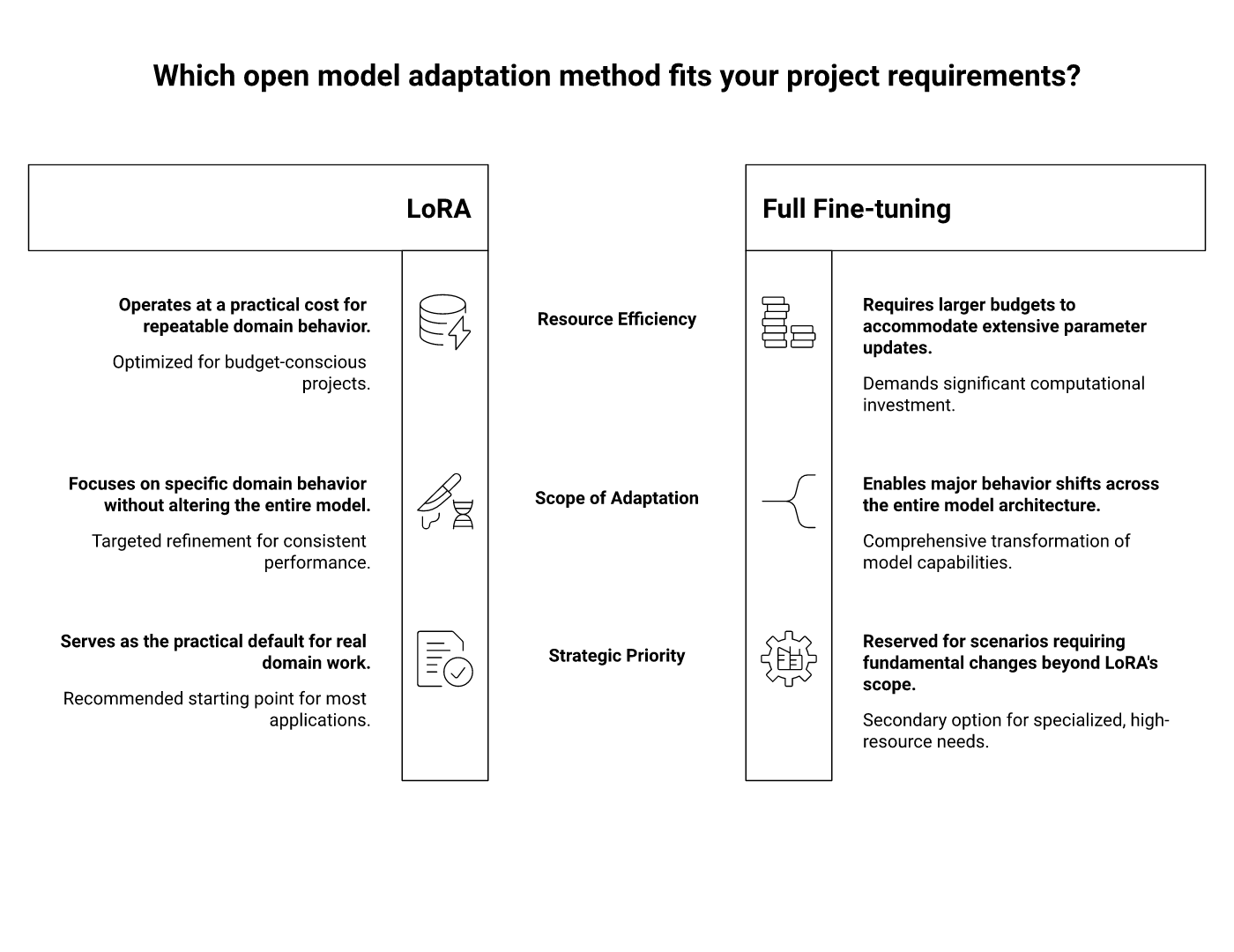 Hiter zemljevid odločanja: za navodila uporabite prompting, za sveža dejstva RAG, LoRA ali QLoRA pa takrat, ko potrebujete ponovljivo domensko vedenje brez operativne bolečine polnega fine-tuninga.
Hiter zemljevid odločanja: za navodila uporabite prompting, za sveža dejstva RAG, LoRA ali QLoRA pa takrat, ko potrebujete ponovljivo domensko vedenje brez operativne bolečine polnega fine-tuninga.
Zakaj je polni fine-tuning običajno napačna prva poteza
Polni fine-tuning se v teoriji sliši čisto. Posodobite vse uteži, obvladujete nastali model in zmogljivost potisnete čim dlje. V praksi je to pogosto drag način, da ugotovite, da je bil nabor podatkov premajhen, cilj premalo jasen ali evalvacija prešibka.
Učenje vseh parametrov modela z več milijardami parametrov zahteva več pomnilnika GPU, več prostora za shranjevanje checkpointov, daljše čase izvajanja in več operativne discipline. Poleg tega ustvari težave z verzioniranjem. Vsak primer uporabe postane še en celoten modelni artefakt, ki ga je treba hraniti, testirati, uvajati in razlagati.
To je še sprejemljivo v raziskovalnem laboratoriju. V poslovnem okolju pa hitro postane naporno.
Kaj spremeni LoRA
LoRA osnovni model zamrzne in uči le majhne adapterske matrike, vstavljene v izbrane plasti. Pameten matematični trik je v tem, da uporabna prilagoditev pogosto živi v veliko manjšem podprostoru, kot nakazuje celotno število parametrov. Namesto da premikate celotno katedralo, ojačate nekaj ključnih nosilnih točk, ki spremenijo vedenje tam, kjer je to pomembno.
Rezultat je učni proces z bistveno manj učljivimi parametri, nižjimi zahtevami po pomnilniku in precej manjšimi artefakti. Ne dostavljate več še enega ogromnega modela. Dostavljate kompakten adapter, ki osnovnemu modelu pove, kako naj se vede v vaši domeni.
To je pomembno iz treh razlogov:
- Iteracije postanejo cenejše. Preizkusite lahko več idej, namesto da vse stavite na en drag učni zagon.
- Specializacija postane modularna. En osnovni model lahko podpira več domenskih adapterjev.
- MLOps postane manj grd. Shranjevanje, vračanje na prejšnje različice in primerjanje adapterjev je precej lažje kot vzdrževanje živalskega vrta popolnoma fine-tunanih modelov.
Zakaj se LoRA še posebej dobro poda odprtim modelom
Odprti modeli so privlačni, ker ekipam dajejo nadzor nad načinom uvajanja, podatkovnimi mejami in izbiro infrastrukture. Ta nadzor pa ima svojo ceno: ko je model vaš, je vaš tudi račun za učenje.
LoRA v tem okolju deluje dobro, ker ohrani glavno prednost odprtih modelov, ne da bi vsak projekt prisilil v program popolnega ponovnega učenja. Ekipe lahko začnejo z dobrim osnovnim modelom, kot so Llama, Mistral, Qwen ali drug model z odprtimi utežmi, nato pa ga prilagodijo svoji domeni z naborom podatkov, ki je dovolj velik, da je uporaben, ne pa dovolj velik, da bi upravičil težko ponovno učenje.
Z drugimi besedami: LoRA omogoča, da se odprti modeli obnašajo kot platforma. Osnovni model ostane stabilen, domensko vedenje pa prebiva v zamenljivih adapterjih.
Kje je LoRA običajno najmočnejša
LoRA praviloma najbolj zasije takrat, ko gre za domensko poravnavo, ne pa za to, da modelu iz nič vcepimo povsem nov pogled na svet.
- Prilagoditev sloga in tona: da izhodi zvenijo kot vaši analitiki, pravniki, kliniki ali ekipe za podporo.
- Oblikovanje nalog: strukturirano izluščevanje, klasifikacija, sledenje navodilom ali odgovori, omejeni s shemo.
- Domensko besedišče: pomoč modelu pri ravnanju z internimi izrazi, kraticami, strukturami dokumentov in robnimi formulacijami.
- Vedenje pomočnika: učenje, kdaj vprašati za pojasnilo, kdaj eskalirati in kako razmišljati znotraj procesnih omejitev.
Manj čarobna pa je pri popravljanju slabega osnovnega modela, kompenzaciji zelo slabih podatkov ali nadomeščanju dobre arhitekture za pridobivanje znanja, kadar je pravi problem pomanjkanje dostopa do znanja in ne prilagoditev vedenja.
Kdaj v igro vstopi QLoRA
Če je LoRA praktična privzeta izbira, je QLoRA njen pragmatični sorodnik za ekipe z bolj omejeno strojno opremo. QLoRA ohrani isto idejo adapterjev, osnovni model pa kvantizira, tako da se učenje lahko izvaja z manj pomnilnika.
To je uporabno, kadar želite prilagoditi dovolj velik odprti model z zmernim proračunom za GPU-je. Prav tako je koristno za hitrejše eksperimentiranje, še posebej v zgodnjih fazah, ko je cilj potrditi smer, ne pa iz benchmarka iztisniti zadnje polovice točke.
Kompromis je v tem, da lahko izbire kvantizacije vplivajo na stabilnost in kakovost izhodov, zato še vedno potrebujete disciplino pri evalvaciji. Poceni učenje je lepo. Poceni napake so še lepše.
Razumen potek učenja odprtih modelov z LoRA
- Izberite osnovni model glede na realnost uvajanja, ne na nečimrnost lestvic. Pomembni so latenca, licenčni pogoji, dolžina konteksta, vedenje tokenizatorja in strošek inferenc.
- Natančno določite vedenjski cilj. Boljše izluščevanje? Boljša struktura odgovorov? Boljše domensko sklepanje? »Naj bo pametnejši« ni učni cilj.
- Pripravite učni nabor, ki je podoben produkciji. Manjši in čistejši nabor podatkov običajno premaga veliko vedro nejasno relevantnega besedila.
- Učite adapter, ne svojega ega. Začnite s konservativnimi ranki in preprostimi nastavitvami, preden izumite junaško iskanje hiperparametrov.
- Evalvirajte proti osnovnemu modelu. Če adapter na resničnih nalogah ne preseže netunanega osnovnega modela, je le dekoracija.
- Adapterje verzionirajte kot produktne artefakte. Obravnavajte jih kot uvajljive komponente z lastniki, logiko povratka in kriteriji sprejema.
Na katere načine ekipe še vedno spodrsnejo
1. Z učenjem začnejo, preden razumejo ozko grlo
Včasih model sploh ni problem. Prompt je šibek, pridobivanje podatkov je slabo ali pa je evalvacijski nabor nesmiseln. LoRA ne more rešiti zmedenega sistemskega dizajna.
2. LoRA uporabljajo za pomnjenje lastniških dejstev
Če je pravi cilj ažuren priklic dejstev, retrieval pogosto spada v arhitekturo. Fine-tunanje vedenja in uporaba RAG za spremenljivo znanje je običajno čistejša kot poskus tetoviranja vsakega novega dejstva v uteži.
3. Uspeh adapterja zamenjajo za univerzalni uspeh
Adapter, ki izboljša en delovni tok, lahko poslabša drugega. Če osnovni model podpira več nalog, si vsak adapter zasluži evalvacijo po konkretnih nalogah, ne pa optimističnega posploševanja.
4. Ignorirajo ergonomijo uvajanja
Pomembni so združevanje adapterjev, strategija serviranja, združljivost s kvantizacijo in benchmarki inferenc. Fine-tuning ni uporaben, če rezultat povzroči dramo pri uvajanju.
Moje stališče
LoRA je preživela vrtiljak trga orodij za LLM z razlogom. Hkrati rešuje ekonomski, inženirski in upravljavski problem.
Učenje odprtih modelov naredi cenejše. Eksperimentiranje naredi hitrejše. In ustvarja manjše, bolj modularne artefakte, ki jih je lažje pregledovati in upravljati. To kombinacijo je nadležno težko premagati.
Bi lahko popolnoma fine-tunan model pri nekaterih nalogah presegel LoRA adapter? Seveda. Toda to ni edino pomembno vprašanje. Pravo vprašanje je, katera metoda vas pripelje do zanesljive domenske zmogljivosti z razumnimi stroški in obvladljivo operativno kompleksnostjo. Za večino ekip odgovor še vedno kaže na LoRA.
Zaključek
Če odprte modele učite za resnično domensko delo, je LoRA še vedno smiseln začetni korak. Spoštuje realnost, da večina organizacij potrebuje boljše vedenje, ne pa lunarne misije popolnega ponovnega učenja. Začnite z osnovnim modelom, natančno določite ozek cilj, previdno učite adapterje in evalvirajte kot odrasli.
To bo premagalo grandiozno strategijo fine-tuninga, zgrajeno na optimizmu in računih za GPU-je.