
LoRA Is Still the Smartest Way to Train Open Models for Real Domain Work
Open models are getting good enough that many teams no longer need to start with a closed API and hope the vendor roadmap eventually matches their domain. The more interesting question now is not whether an open model can be adapted. It is how to adapt it without burning money, time, and operational patience.
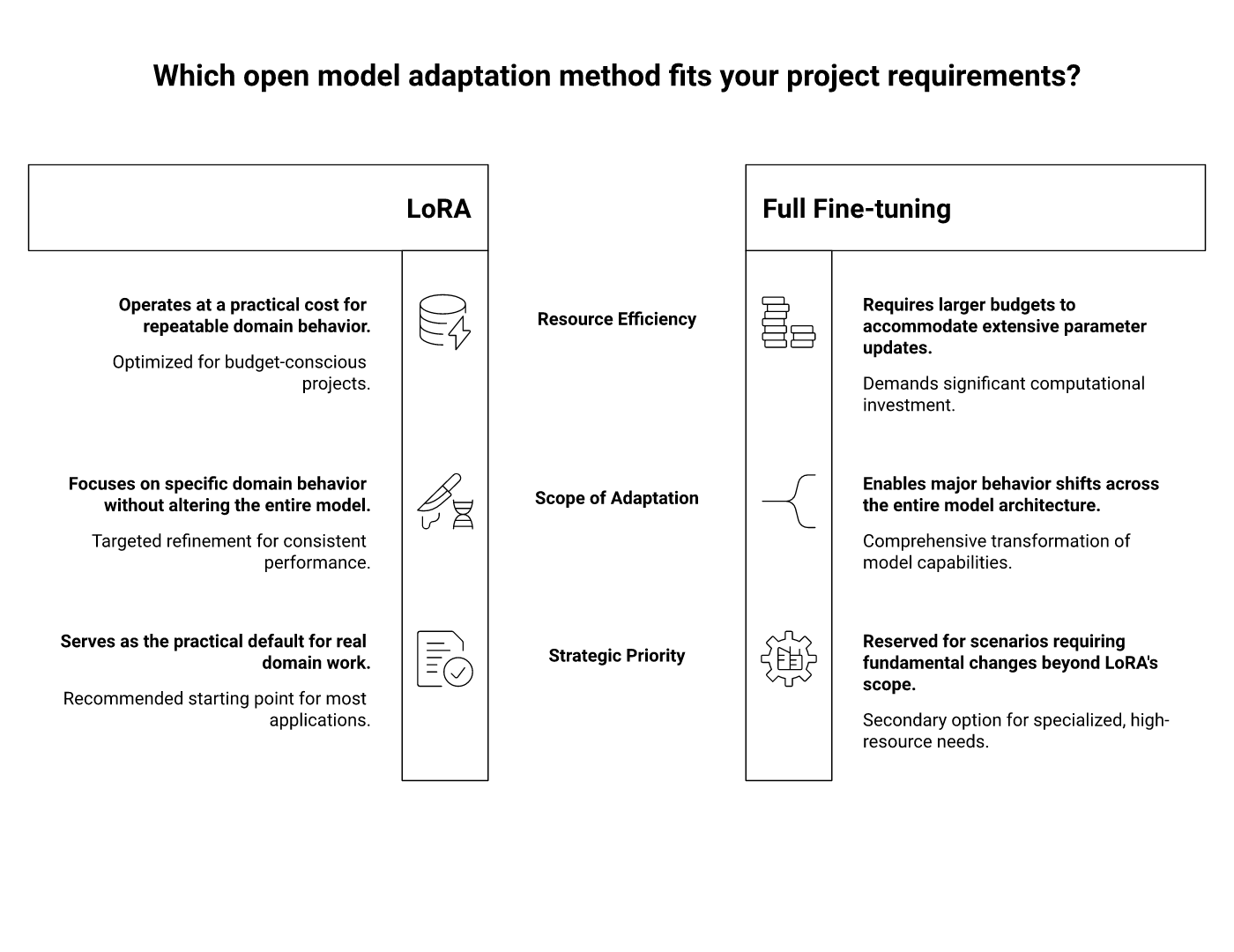
For most organisations, the practical answer is still LoRA — Low-Rank Adaptation. Not because it is fashionable, but because it hits the awkward middle ground that real projects live in: limited compute, imperfect data, fast iteration pressure, and a need to keep the base model stable while specialising behaviour.
If you want to train an open model for domain work, LoRA is usually the first method worth trying and the last method you should abandon lightly.
Why full fine-tuning is usually the wrong first move
Full fine-tuning sounds clean in theory. Update all the weights, own the resulting model, and push performance as far as possible. In practice, it is often an expensive way to learn that your dataset was too small, your objective was too fuzzy, or your evaluation was too weak.
Training all parameters of a multi-billion-parameter model demands more GPU memory, more checkpoint storage, longer run times, and more operational discipline. It also creates a versioning headache. Every use case becomes another full model artifact to store, test, deploy, and explain.
That is tolerable in a research lab. It is tiresome in a business environment.
What LoRA changes
LoRA freezes the base model and trains only small adapter matrices injected into selected layers. The clever mathematical trick is that useful adaptation often lives in a much smaller subspace than the full parameter count suggests. So instead of moving the whole cathedral, you reinforce a few structural points that change behaviour where it matters.
The result is a training setup with dramatically fewer trainable parameters, lighter memory requirements, and much smaller artifacts. You are no longer shipping another giant model. You are shipping a compact adapter that tells the base model how to behave in your domain.
That matters for three reasons:
- Iteration gets cheaper. You can test more ideas instead of betting everything on one expensive run.
- Specialisation becomes modular. One base model can support multiple domain adapters.
- MLOps gets less ugly. Storing, rolling back, and comparing adapters is much easier than maintaining a zoo of fully fine-tuned models.
Why LoRA fits open models especially well
Open models are attractive because they give teams control over deployment, data boundaries, and infrastructure choices. But that control comes with a catch: once the model is yours, the training bill is also yours.
LoRA works well in this setting because it preserves the main advantage of open models without forcing every project into a full retraining programme. Teams can start with a solid base model such as Llama, Mistral, Qwen, or another open-weight model, and then adapt it to their domain using a dataset that is large enough to be useful but not large enough to justify heavy retraining.
In other words, LoRA lets open models behave like a platform. The base model stays stable, while the domain behaviour sits in swappable adapters.
Where LoRA is usually strong
LoRA tends to shine when the task is about domain alignment rather than teaching a model an entirely new worldview from scratch.
- Style and tone adaptation: making outputs sound like your analysts, lawyers, clinicians, or support teams.
- Task formatting: structured extraction, classification, instruction following, or schema-constrained answers.
- Domain vocabulary: helping the model handle internal terminology, abbreviations, document structures, and edge-case phrasing.
- Assistant behaviour: teaching when to ask for clarification, when to escalate, and how to reason inside process boundaries.
What it is less magical at: fixing a bad base model, compensating for terrible data, or replacing a proper retrieval architecture when the real problem is missing knowledge access rather than behaviour adaptation.
When QLoRA enters the conversation
If LoRA is the practical default, QLoRA is the pragmatic cousin for teams with tighter hardware. QLoRA keeps the same adapter idea but quantizes the base model so training can happen on less memory.
This is useful when you want to adapt a decent-sized open model on a modest GPU budget. It is also useful for faster experimentation, especially in early stages when the goal is to validate a direction rather than squeeze the final half-point out of a benchmark.
The trade-off is that quantization choices can affect stability and output quality, so you still need evaluation discipline. Cheap training is nice. Cheap mistakes are nicer.
A sane workflow for training open models with LoRA
- Pick a base model for the deployment reality, not for leaderboard vanity. Latency, licence terms, context length, tokenizer behaviour, and inference cost matter.
- Define the behavioural objective precisely. Better extraction? Better answer structure? Better domain reasoning? “Make it smarter” is not a training objective.
- Curate a training set that looks like production. A smaller, cleaner dataset usually beats a large bucket of vaguely relevant text.
- Train the adapter, not your ego. Start with conservative ranks and straightforward settings before inventing a heroic hyperparameter search.
- Evaluate against the baseline model. If the adapter does not beat the untuned base model on real tasks, it is decorative.
- Version adapters as product assets. Treat them like deployable components with owners, rollback logic, and acceptance criteria.
The failure modes teams keep stumbling into
1. Training before they understand the bottleneck
Sometimes the model is not the problem. The prompt is weak, the retrieval is poor, or the evaluation set is nonsense. LoRA cannot rescue confused system design.
2. Using LoRA to memorize proprietary facts
If the real need is up-to-date factual recall, retrieval often belongs in the architecture. Fine-tuning behaviour and using RAG for volatile knowledge is usually cleaner than trying to tattoo every new fact into the weights.
3. Treating adapter success as universal success
An adapter that improves one workflow may degrade another. If a base model supports multiple tasks, every adapter deserves task-specific evaluation, not wishful generalization.
4. Ignoring deployment ergonomics
Adapter merging, serving strategy, quantization compatibility, and inference benchmarks matter. A fine-tuning run is not useful if the result creates deployment drama.
My view
LoRA has survived the churn of the LLM tooling market for a reason. It solves an economic problem, an engineering problem, and a governance problem at the same time.
It makes training open models cheaper. It makes experimentation faster. And it creates smaller, more modular artifacts that are easier to review and operate. That combination is annoyingly hard to beat.
Could a fully fine-tuned model outperform a LoRA adapter on some tasks? Of course. But that is not the only question that matters. The real question is what method gets you to reliable domain performance with acceptable cost and manageable operational complexity. For most teams, that answer still points to LoRA.
Conclusion
If you are training open models for real domain work, LoRA is still the sensible starting point. It respects the reality that most organisations need better behaviour, not a moonshot retraining programme. Start with the base model, define the narrow objective, train adapters carefully, and evaluate like an adult.
That will beat a grand fine-tuning strategy built on optimism and GPU invoices.