
The Fair Game: Keeping AI Fair in a Moving World
Hello everyone. Today I want to talk about a very big topic for "AI safety": the concept of fairness. By this, we mean a system's ability to withstand the distribution shifts and systematic predictive disparities that can creep into decision pipelines.
You see, most models are trained on historical datasets. These datasets reflect past inequalities, imbalanced representation, and embedded social norms. So when we train models on that data, they don't just learn the patterns we're hoping they'll learn, they also learn (and can actually amplify) the distortions we wish weren't there at all.
 We generally refer to this phenomenon as bias. Not statistical estimator bias and not optimization bias, those are different. Here we're talking about social/group fairness bias. The tendency to produce systematically different outcomes, error rates, or acceptance probabilities across protected groups. Even when we're trying deliberately to design the system to do the opposite.
We generally refer to this phenomenon as bias. Not statistical estimator bias and not optimization bias, those are different. Here we're talking about social/group fairness bias. The tendency to produce systematically different outcomes, error rates, or acceptance probabilities across protected groups. Even when we're trying deliberately to design the system to do the opposite.
How we usually fight bias
Efforts to combat this particular type of bias and to establish fairness in these models tend to focus on two processes:
- Auditing: Measuring whether a deployed model exhibits statistical disparities across protected groups.
- Debiasing: Modifying the data, training procedure, or outputs of a model, to reduce those disparities.
It might seem like these would go hand-in-hand, but they're usually treated as static and separate. Auditors measure bias after the fact. Debiasing algorithms optimize against a fixed fairness definition. But these processes don't work together in any direct meaningful way.
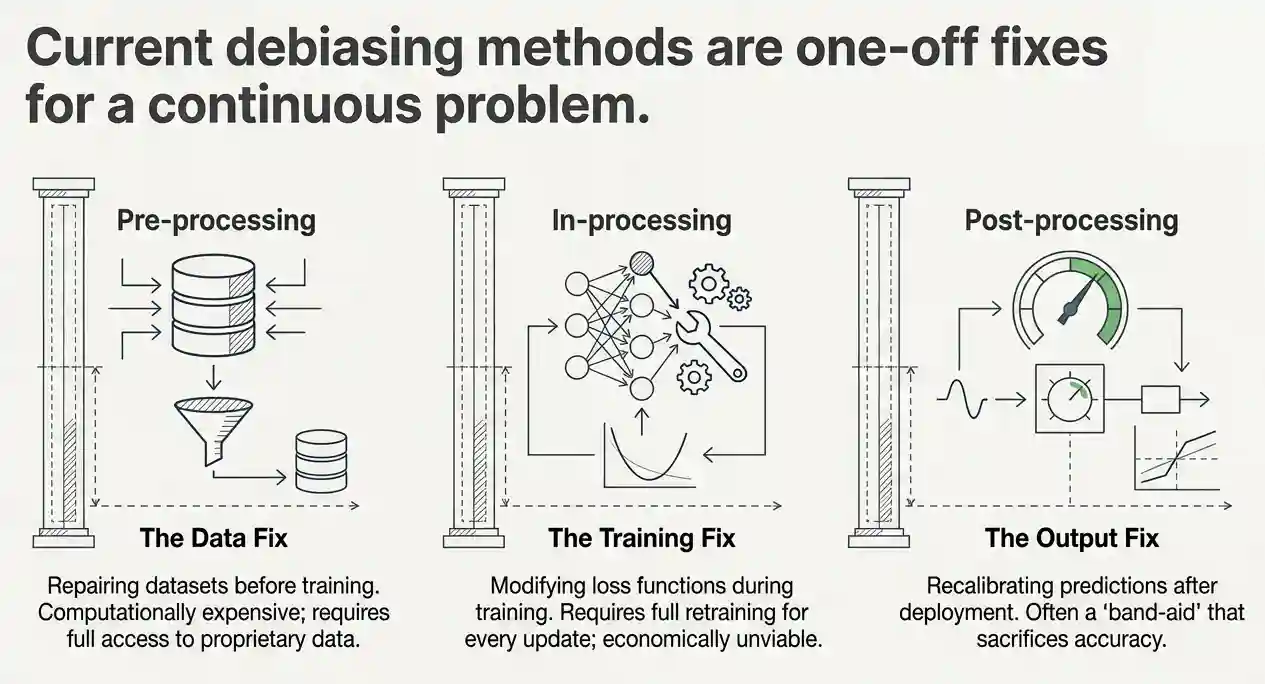
The debiasing landscape
To appreciate the authors' contribution, it helps to understand what debiasing currently looks like. Depending on where in the machine learning pipeline the intervention happens, debiasing methods fall into three families: pre-processing approaches that transform the training data before the model ever sees it, in-processing techniques that alter the loss function or training procedure itself, and post-processing strategies that adjust predictions after they leave the model without touching any internals. Each family carries its own trade-offs, but they all share one critical assumption: that the definition of "fair" has already been settled before deployment. The fairness metric is essentially hardcoded from day one and never revisited.
What auditors actually produce
Auditors, meanwhile, work by sampling a model's inputs and outputs and then estimating the degree of bias present. The gold standard here is what the literature calls a PAC estimate, short for "probably approximately correct." It is a formal statistical guarantee that the bias estimate falls within a small error margin of the true value, with high probability, across the entire input distribution. Reaching that guarantee without consuming enormous volumes of data is the hard part. Existing auditors split into two camps: verification-based approaches that check whether bias falls below a given threshold using minimal samples, and estimation-based approaches that directly quantify the bias level.
The widening gap
The problem is: real systems evolve. Data shifts. Regulations change. Ethical norms move. And when this happens, these fairness mechanisms don't keep up. Why? Because when you treat them separately, you lose the ability for the system to adapt in real time.
There is no structured feedback loop to align the model with updated fairness goals. And there is no mechanism for the auditor to update what it measures. Today, auditors simply produce reports. Those reports land somewhere. Perhaps someone reads them, perhaps nobody does. Perhaps the model eventually gets retrained, or perhaps it stays frozen. There is no formal channel connecting the auditor's findings back to the debiasing algorithm. No form of dynamic adaptation. A model that was audited and corrected in 2021 against a particular fairness metric is not necessarily fair in 2026, even if nothing inside the model was deliberately changed. What we need is a way to audit and correct our models continuously without having to retrain them from scratch or lock ourselves into a single definition of fairness.
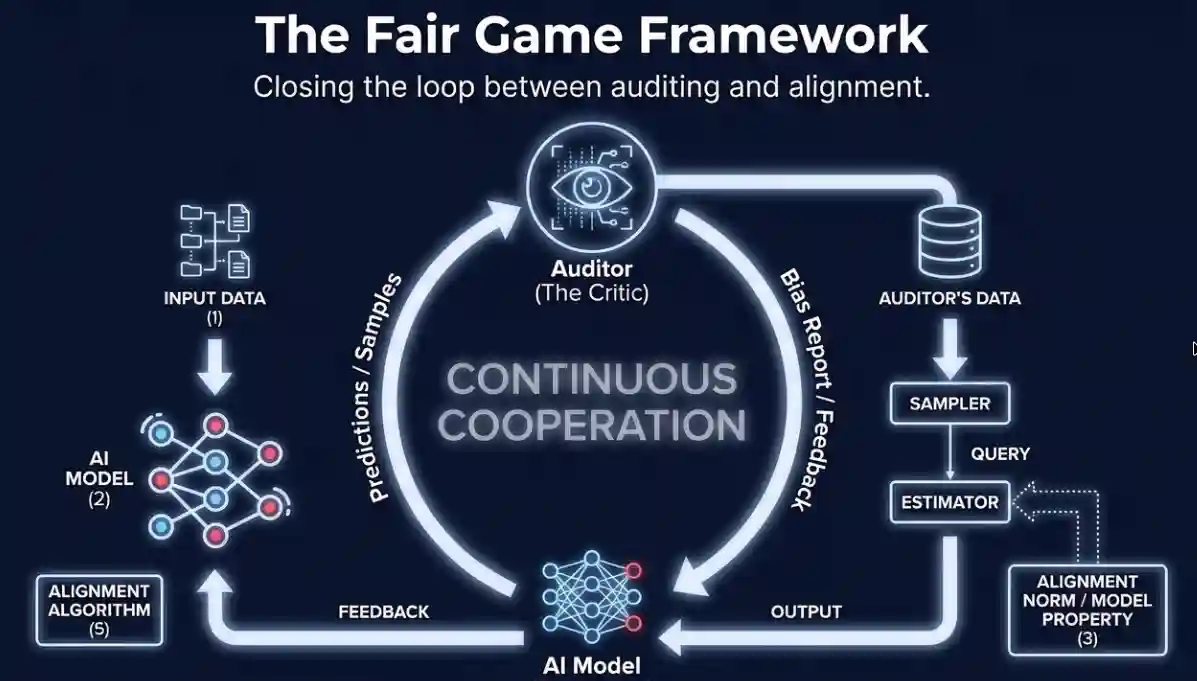
The "Fair Game" Framework
That is where the new research comes in. In it, the authors propose an auditor-alignment framework called Fair Game. It wraps a model inside a loop, between an auditor and a debiasing algorithm.
The auditor measures bias over time. The debiasing component adapts the system in response. And the whole interaction gets structured as a reinforcement learning problem. It morphs fairness optimization from a one-time constraint into an evolving interaction. One that adapts to new data, and aligns itself closer and closer to our fairness criteria.
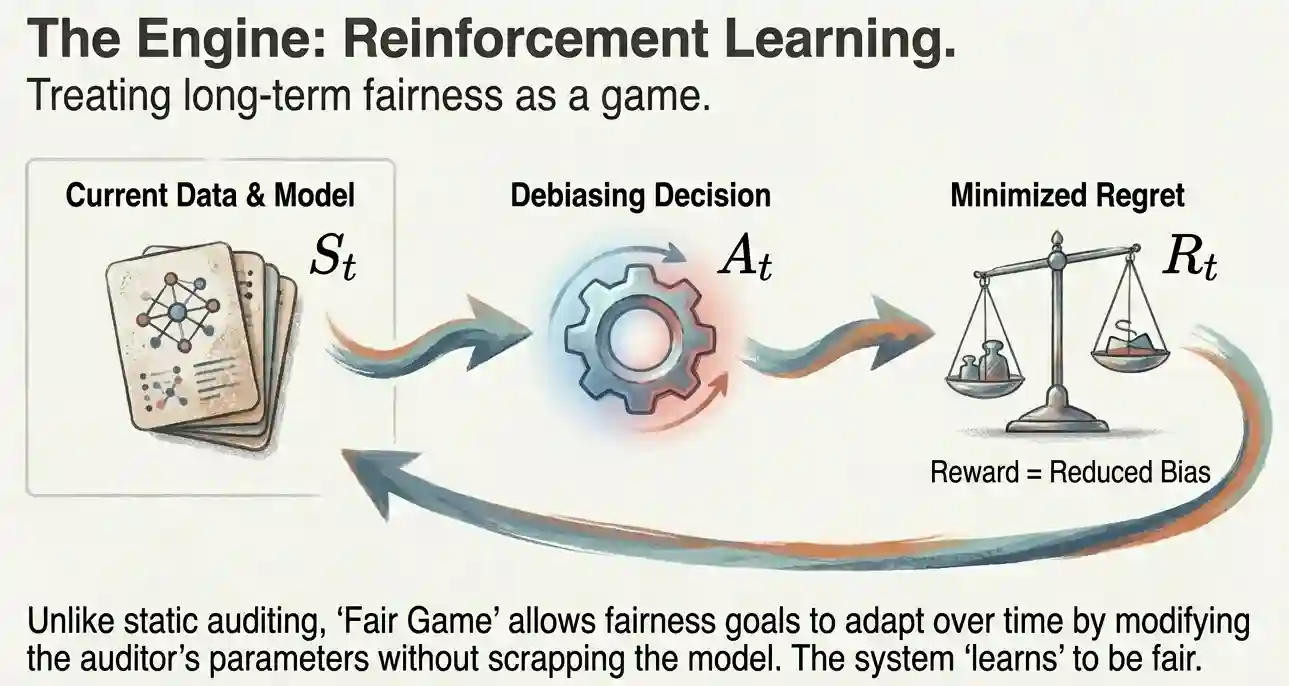
The core mechanism works like this: at each time step, the debiasing algorithm acts as an RL agent interacting with an environment composed of the deployed model, the incoming data stream, and the bias reports generated by the auditor. The measured bias at each step serves as the cost signal. The agent's objective is to drive that cost down over time, even as the underlying data and the definition of bias itself are shifting beneath it.
Formally, this is modelled as a two-player stochastic game. Both the auditor and the debiasing algorithm maintain their own objectives, and each player's behaviour directly shapes the other's operating conditions.
Player 1 and Player 2
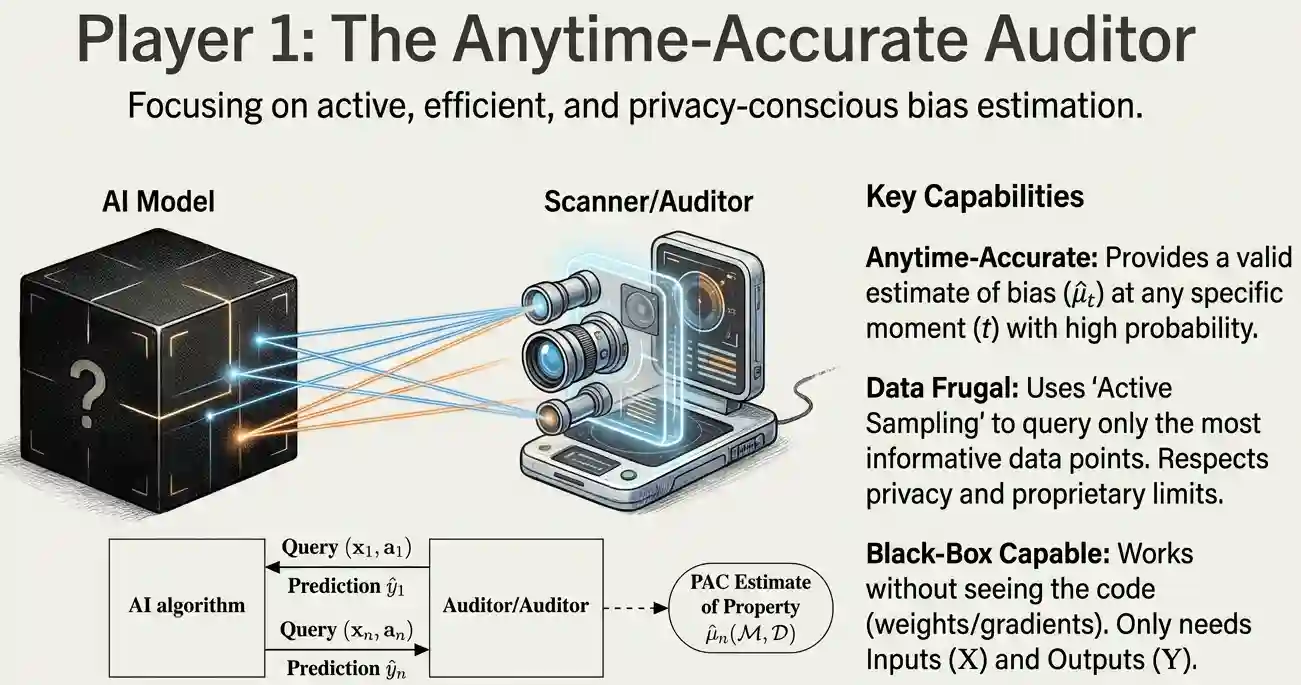
The Anytime-Accurate Auditor (Player 1) provides a valid estimate of bias at any specific moment with high probability. The key property here is that it is "anytime-accurate": for any chosen error tolerance and confidence level, it can deliver a bias estimate that stays within that tolerance with high probability, and it can do this simultaneously at every time step rather than only at the conclusion of a batch evaluation. It is data frugal, meaning it uses active sampling to query only the most informative data points while respecting privacy. It is even black-box capable, so it works without needing to see the internal code.
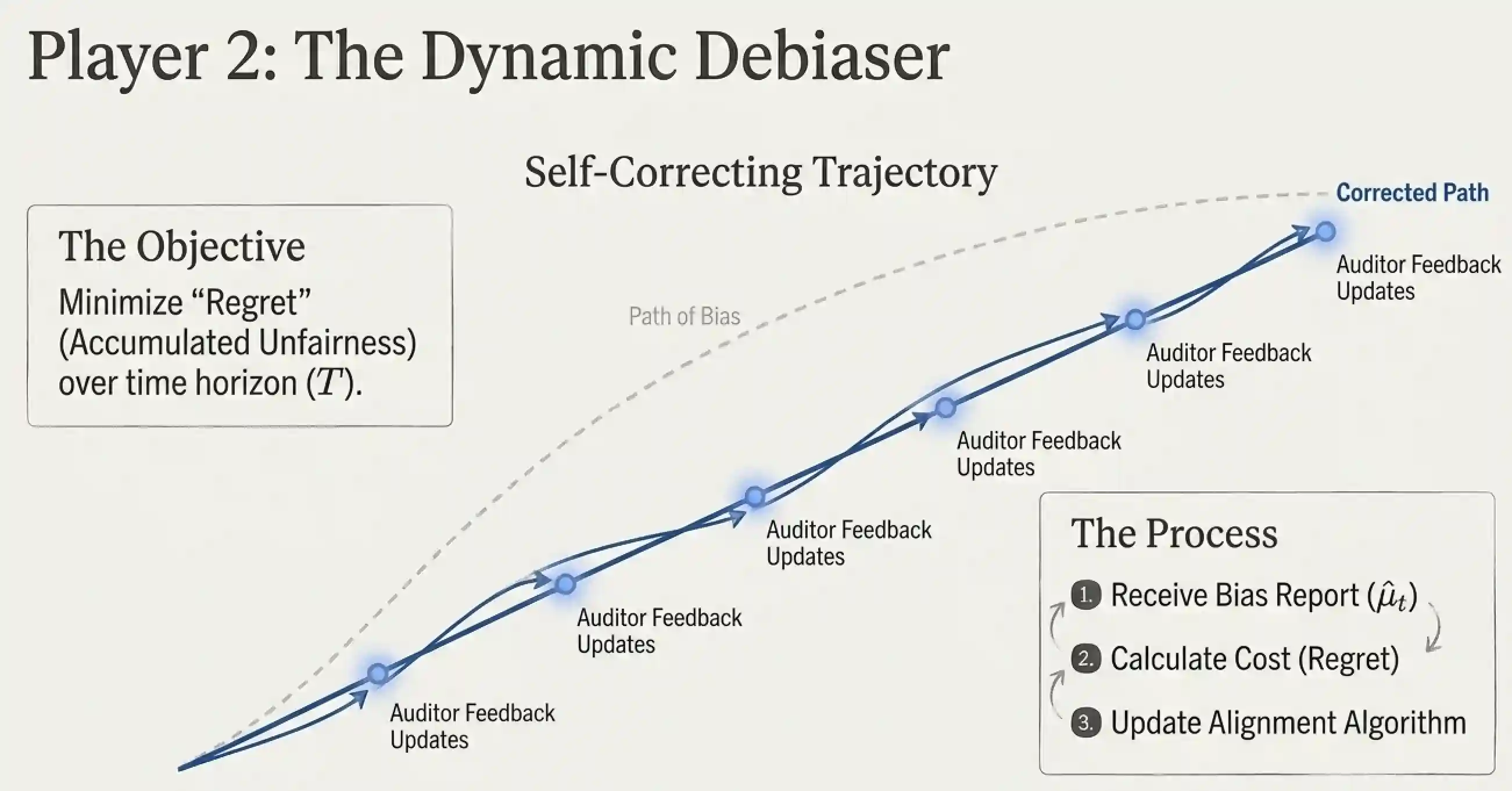
The Dynamic Debiaser (Player 2) has one objective: to minimize Regret (accumulated unfairness) over time. Regret here is defined precisely: it is the gap between the average bias the deployed system actually achieved and the minimum average bias that any theoretically optimal auditor-debiaser pair could have achieved given the same data stream. It receives the bias report, calculates the cost, and updates the alignment algorithm to keep the model on a self-correcting path.
Rules for a successful game
There are several challenges the system must handle if this is to actually work:
- Data Frugality: Auditing is fundamentally a sampling problem. The auditor must reach statistically credible conclusions from as few observations as possible, which matters enormously when data collection is expensive or privacy-constrained.
- Manipulation Proofness: Any entity that knows it is about to be audited has an incentive to present a curated slice of inputs that make the model appear fairer than it really is. The auditor must be robust enough that such strategic data presentation cannot fool it.
- Adaptive and Dynamic Behaviour: The system must permit fairness goals to be updated over time, simply by reconfiguring or swapping out the auditor, without requiring the entire debiasing pipeline to be retrained from scratch.
- Structured and Preferential Feedback: Not all ethical norms reduce to clean metrics. Sometimes a human reviewer examines an outcome and flags it as wrong even though no formal definition was violated. The system integrates RLHF (Reinforcement Learning from Human Feedback) to accommodate this kind of qualitative, context-dependent judgement.
How the authors validated the framework
It is worth noting that the evaluation here is entirely analytical. Rather than running benchmarks or experiments, the authors constructed a formal mathematical proof, closer in spirit to the logical proofs of geometry than to a hypothesis test in statistics. They formalised what it means for an auditor to be anytime-accurate, defined regret for the joint pair, catalogued the conditions under which long-run average bias can be minimised, derived the sample complexity requirements, established the manipulation-proof guarantees, and formalised the stability criteria for the two-player interaction. Under certain assumptions about data drift and model updates, they prove that the system can converge toward lower average bias over time. This is, in other words, an architecture specification with provable properties rather than a fully engineered production pipeline. Any build-out or empirical validation will need to follow in a separate study.
Why this matters: Lessons from NYC
We can see why this is needed by looking at NYC Local Law 144. It fell short because it relied on simple metrics and only required audits once a year. This created a "checkbox culture" without ensuring long-term fairness. The Fair Game proposes a dynamic perspective to move past these "static snapshots."
At the end, this study shows us that fairness can be reframed as a dynamic systems problem. It's less about defining the right metric and more about designing feedback mechanisms that keep these systems aligned over time.
Source Research
If you want to go deeper on the game-theoretic formulations, the formal proofs, or the taxonomy of existing auditors the authors assembled, you can download the full paper here:
The Fair Game: Auditing & debiasing AI algorithms over time.
